[!NOTE] This article was originally written in 2019 on LinkedIn.
Overview
C Build Process is considered one of the most important topics in the field of Embedded Software and it’s the most famous question you will be asked in any Embedded Software interview.
Today we will talk about each step of this process in details to help you get a better understanding of this process.
C Build Process is the process of converting the high level source code representation of your embedded software into an executable binary image. This Process involves many steps and tools but the main three distinct steps of this process are:
- Each of the source files must be compiled or assembled into an object file.
- All of the object files that result from the first step must be linked together to produce a single object file, called the relocatable program.
- Physical memory addresses must be assigned to the relative offsets within the relocatable program in a process called relocation.
The result of the final step is a file containing an executable binary image that is ready to run on the embedded system.
So, let’s begin to discus every step of this process in more details to be able to understand it better.
1. Preprocessor
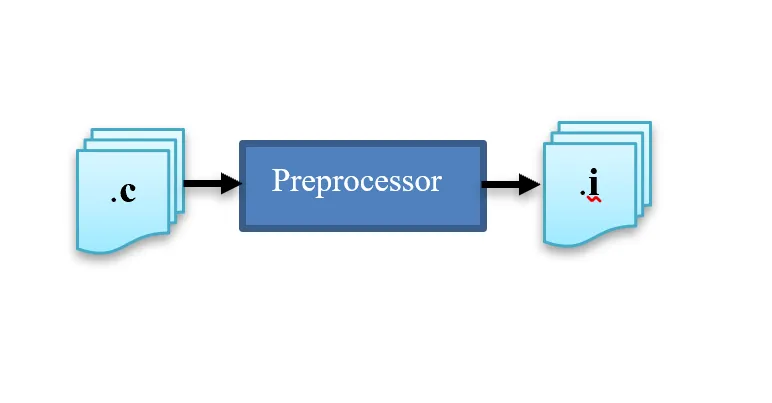
Preprocessing is the first stage of C Build process in which all the preprocessor directives are evaluated.
The input file for this stage is *.c file.
The output file is *.i or preprocessed file.
The preprocessor strips out comments from the input c file. Evaluate preprocessor directive by making substitution for lines started with #, and then produces a pure C code without any preprocessor directives.
Note that if a bug/error happened in the preprocessor stage you normally won’t know its place as the output of the preprocessor goes directly into compiler, the error will be likely at the lines you used the preprocessor directive.
2. Compiler
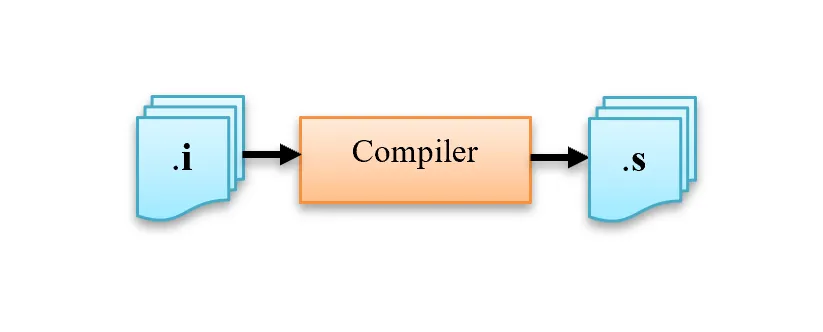
In this stage the C code gets converted into architecture specific assembly by the compiler; this conversion is not a one to one mapping of lines but instead a decomposition of C operations into numerous assembly operations. Each operation itself is a very basic task.
The input file for this stage is *.i file.
The output file is *.s or *.asm file.
To understand what exactly happens in this stage, we have to know how the compiler works and what is its components.

The first part of the compiler is called Front End: in which, the analysis of program syntax and semantics happens.
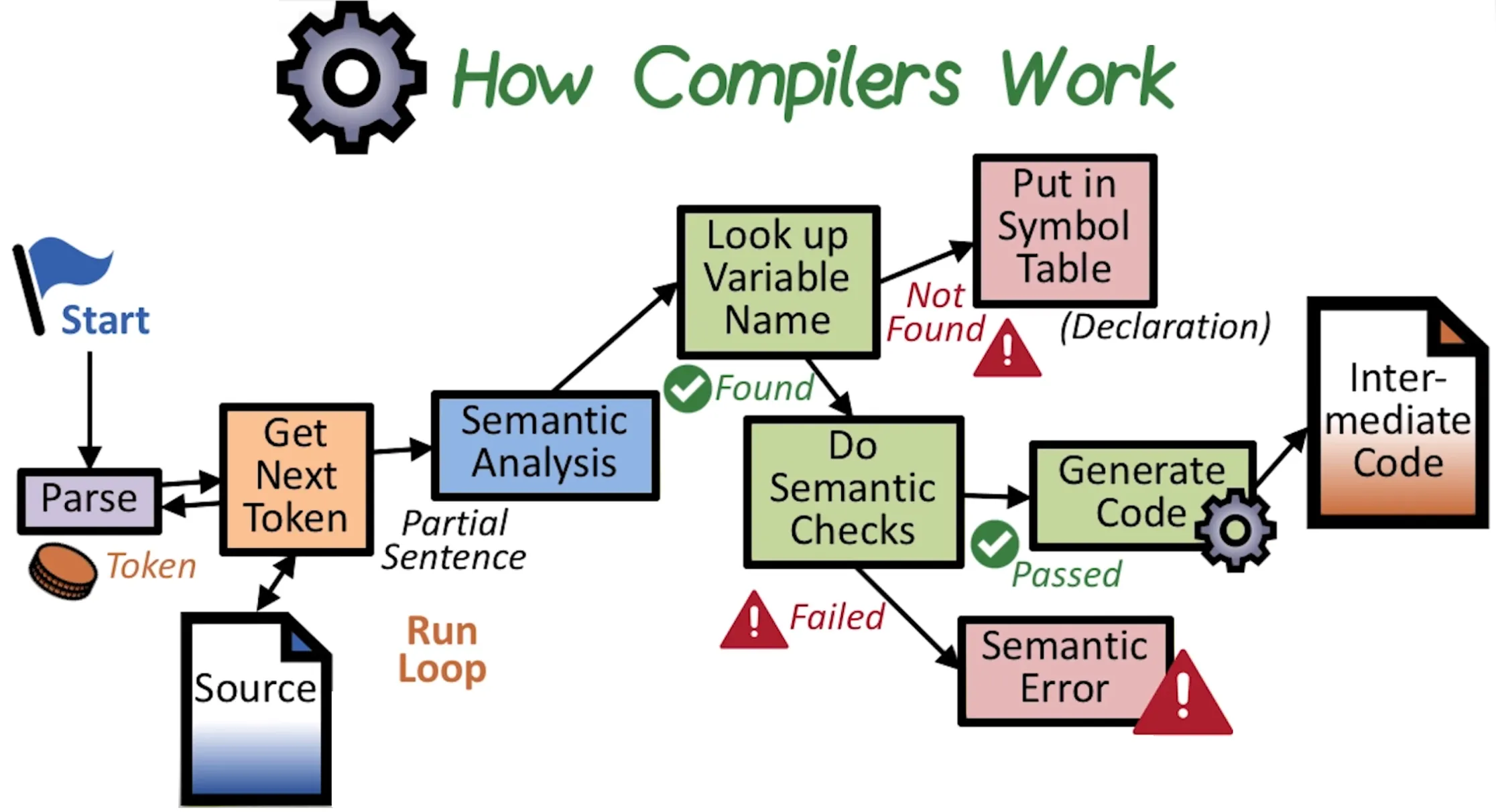
First stage of the front-end part of the compiler is scanning the input text and Tokenization by identifying tokens such as keywords, identifiers, operators, and literals, then passing the scanned token to the parsing tool that ensures tokens are organized according to C rules to avoid compiler syntax errors.
Second stage of the front-end of the compiler is checking if the sentence that has been parsed has the right meaning. And, this semantic check, if it fails you get a Semantic Error.
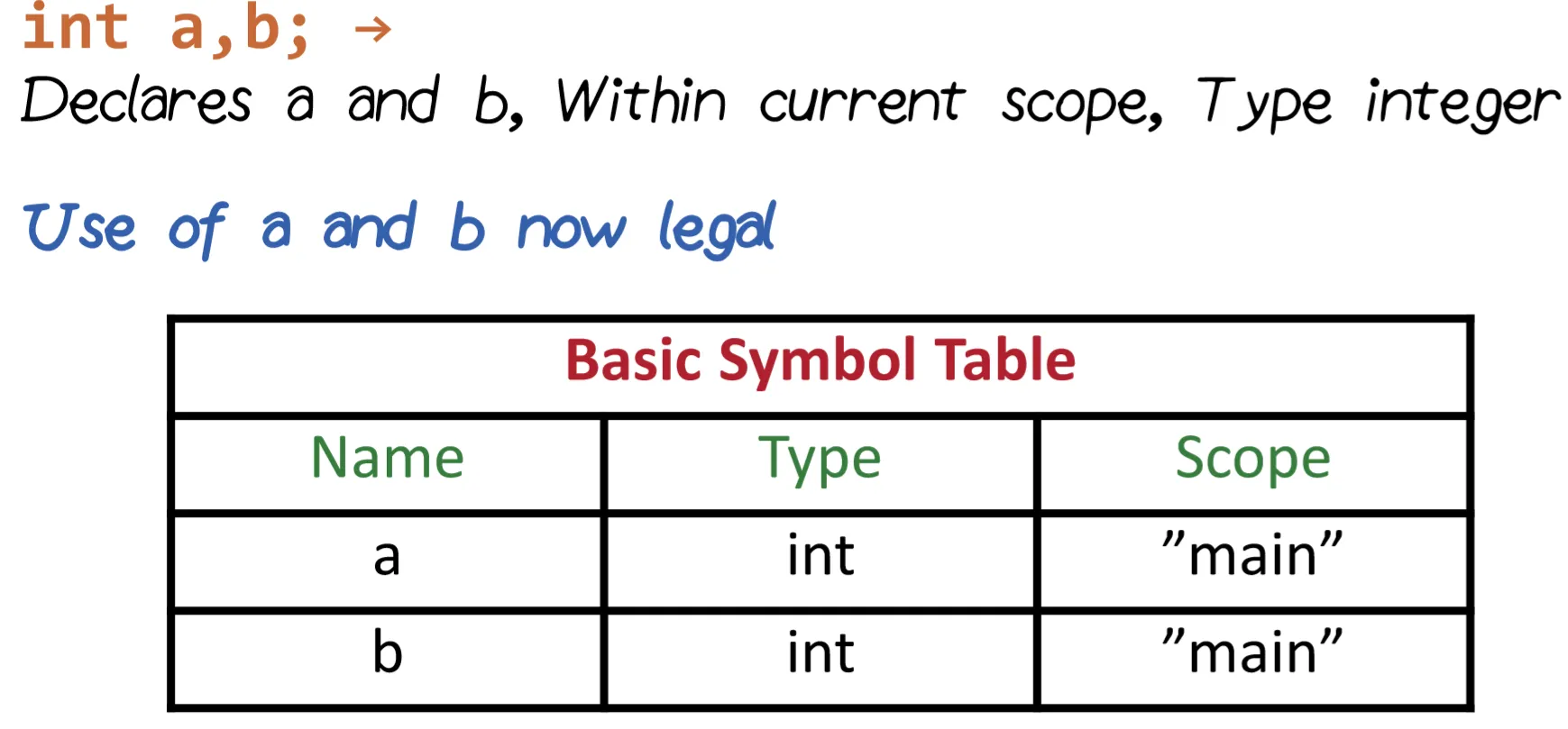
One of the key things that really happens in the semantic analysis is to do with all variables that are present in the program. And for that matter, the compiler maintains the information of all the declared variables in a structure called symbol table. Once the variable is locked up, it gets its attributes; the attributes are its type, scope, and so on.
When the statement is found to be semantically meaningful and is correct, the compiler undertakes its next action, which is to translate this sentence into an internal representation called as the intermediate representation.
Types of semantic errors:
- Undeclared variable that is being used without declaration.
- Unavailable variables in a given scope, although they are declared.
- Incompatible types.
Symbol Table: The symbol table shows which variables are declared in the program and which are available within current scope.
The second part of the compiler is called Back End: in which, the optimization and code generation happens.
First stage of the back-end part of the compiler is optimization. There are many forms of optimization such as transforming code into smaller or faster but functionally equivalent, inline expansion of functions, dead code removal, loop unrolling, and register allocation.
The last stage of the back-end part of the compiler is the code generation; in which the compiler converts the optimized intermediate code structure into assembly code.
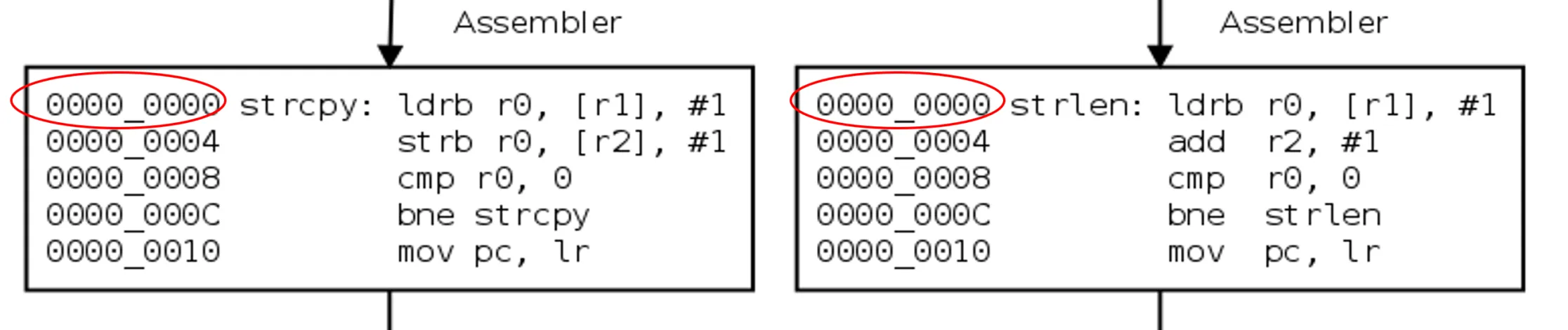
3. Assembler
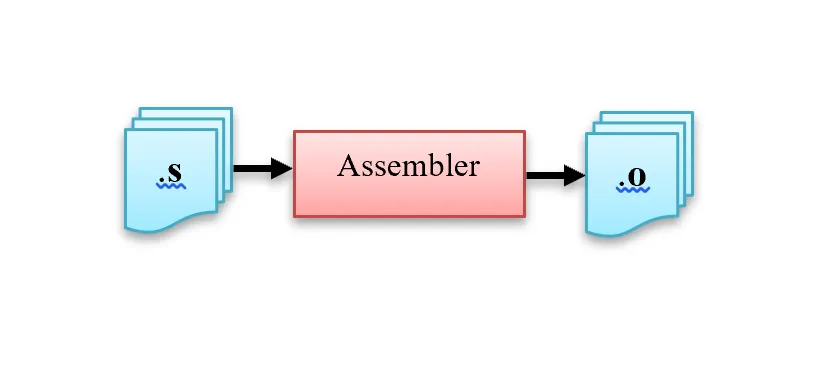
In this stage the assembly code that is generated by the compiler gets converted into object code by the assembler.
The input file for this stage is *.asm file.
The output file is *.o or *.obj file.
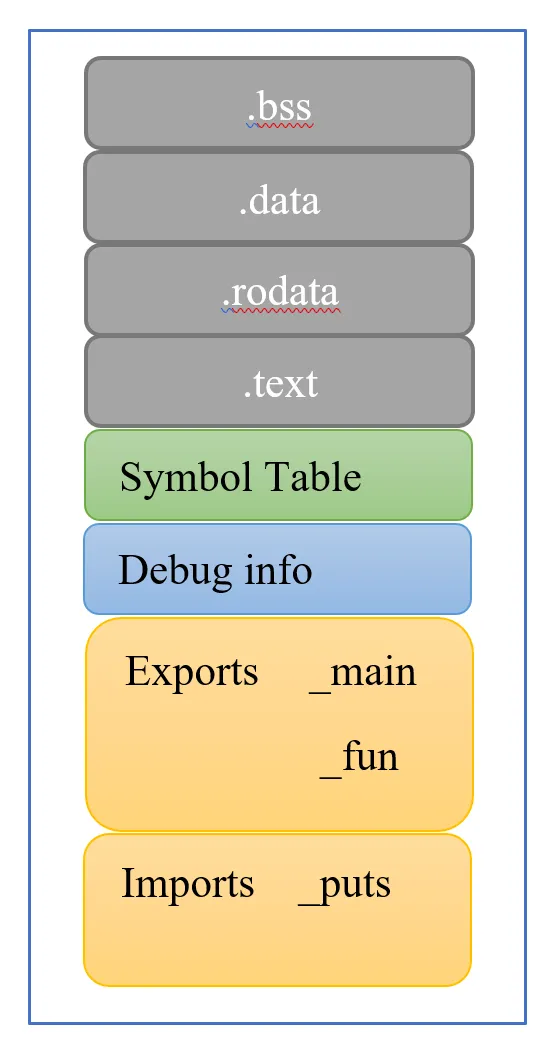
Memory Sections:
- .text Segment: Contains executable instructions.
- .data Segment: Contains global and static variables initialized by the programmer.
- .bss Segment: Contains global and static variables initialized to zero or uninitialized.
- stack Segment: Stores temporary data like local variables and return addresses.
- heap Segment: Dynamic data storage.
4. Linker
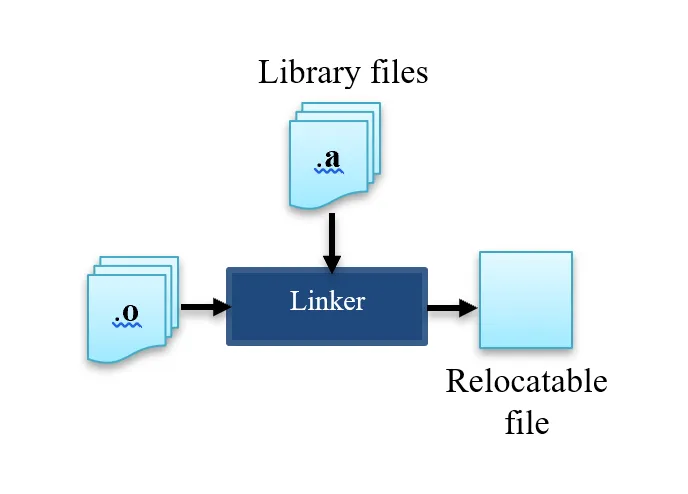
The linker combines different object files into one relocatable file. Operations performed:
- Symbol resolution: Resolving references to labels defined in other files.
- Relocation: Changing addresses already assigned to labels.
Section Merging:
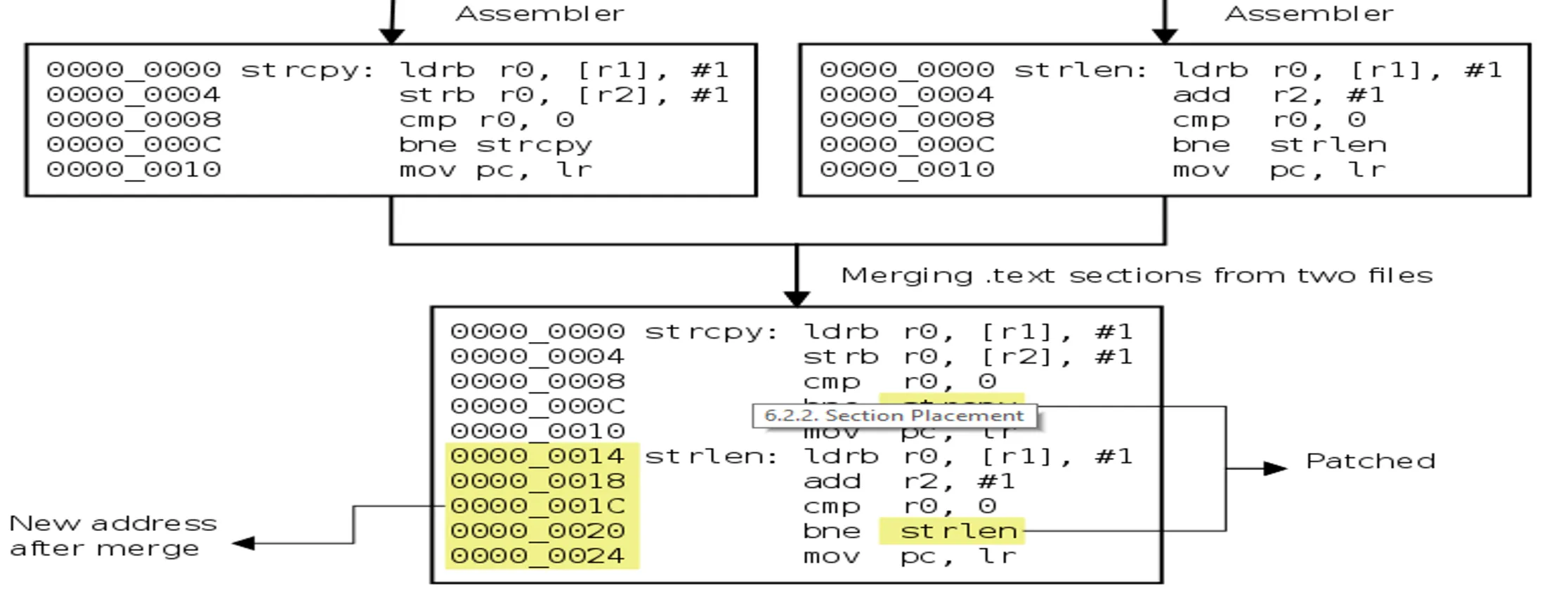
Section Placement:
5. Locator
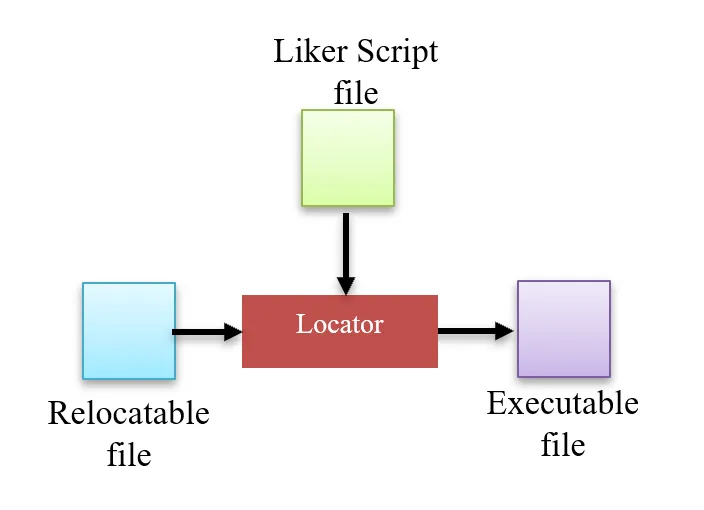
The locator assigns physical addresses to the relocatable file using a Linker Script File (LCF). The LCF defines the physical memory layout (Flash/SRAM) and placement of the different program regions.
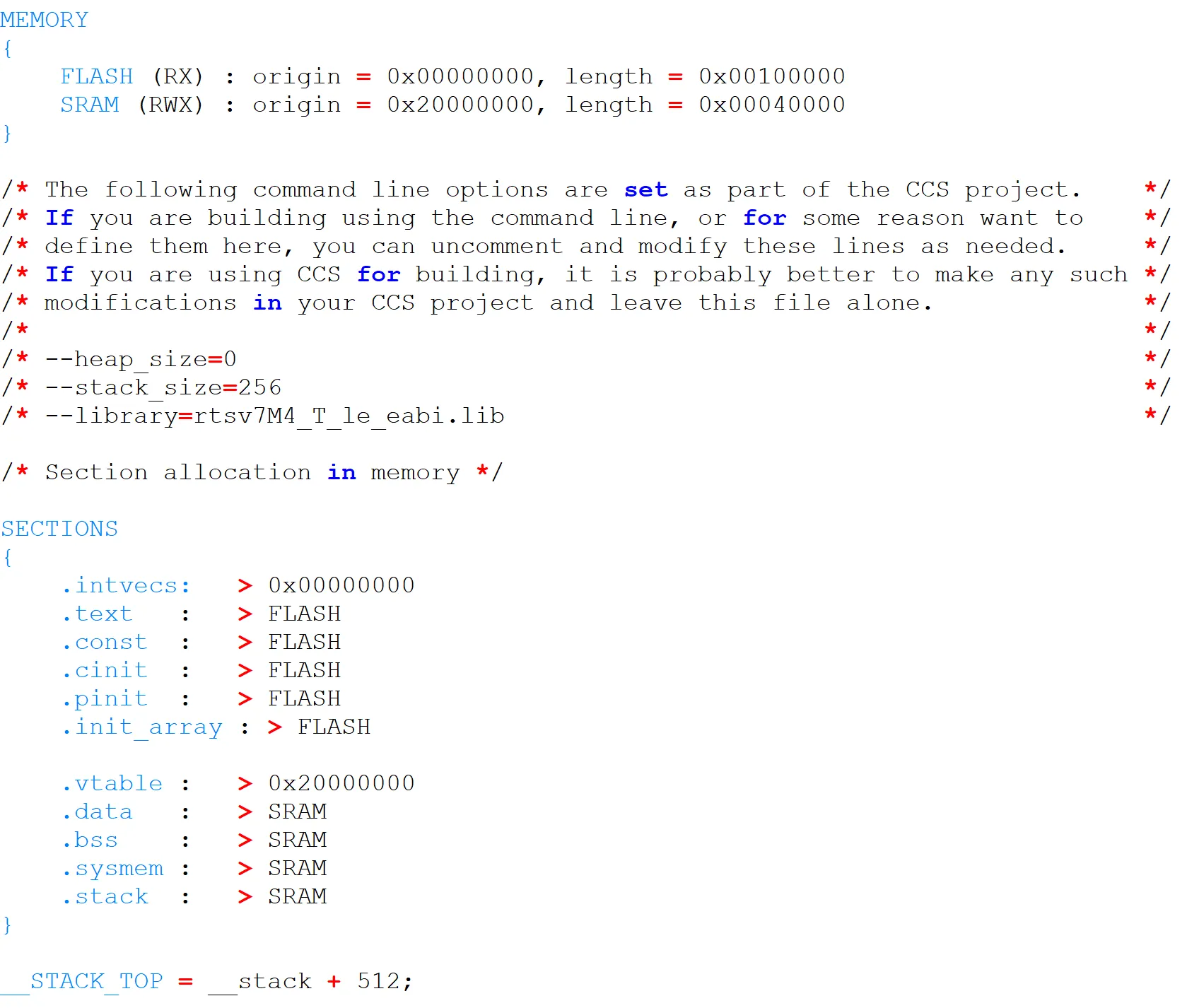
The final output is an executable binary image ready to be loaded to the embedded target.
References
- Compilers: Theory and Practice - Udacity
- Programming Embedded Systems: Anthony Massa and Michael Barr
- Introduction to Embedded Systems Software - Coursera (University of Colorado Boulder)
- Introduction to C Programming Arabic, Eng. Amr Ali - YouTube